
The reverse-engineering programming code Decanonization subtracts the areas tagged by crowdworkers in the images that train computer vision.
Bruno Moreschi is an artistic researcher. Since 2023, he has been a fellow conducting research at LIAS – Leuphana University Institute for Advanced Studies. There, he develops new methodologies to train computer vision, particularly inspired by critical pedagogy and conceptual art. His projects are recognized by grants, exhibitions and institutions such as ZKM, Van Abbemuseum, Collegium Helveticum ETH, 33rd São Paulo Art Biennial, University of Cambridge and Bauhaus Fellowship.
For eight years, I have been researching, exchanging ideas with, and learning from a specific group of workers: those who train computers to “see” the world. In specialized literature on fields such as Artificial Intelligence and platform labor studies, these workers are referred to as microworkers or crowdworkers. They are individuals who perform small, often repetitive tasks through online platforms as part of a larger workforce. These tasks, commonly known as microtasks, can include data entry, content moderation, surveys, or image labeling. Examples of these workers are content moderators, data labelers, and product reviewers. Crowdworkers play a crucial role in the development of computer vision, particularly in tagging and organizing the images in datasets used to train machines.
It is difficult to obtain precise data about them, such as their nationalities, ages and how many people they are in total is not known. Such opacity makes it difficult to better understand their work routines and makes them invisible workers—as if computer vision processes were fully automatic. Remote work platforms like Amazon Mechanical Turk (AMT), where many of them are employed, do not disclose such information. A 2018 study estimated that there were 250,000 MTurkers on Amazon Mechanical Turk. That same year, it was estimated that 75% of these workers were based in the US, 16% in India, and 9% in other countries. Another study revealed that 2,000 to 5,000 workers were actively engaged on the platform at any given moment. What is known for certain, however, is that they are extremely low-paid, and their work is decontextualized in relation to the kind of algorithms and AI tools they are training. In most cases, the services offered by AMT are explained in a very succinct manner, making it very clear to these workers that they are not in fact being considered co-authors of what is being trained. This opacity drives my continued engagement with these crowdworkers—through research about them and by forming emotional connections and working with them. If it is impossible to grasp the exact size of this crowd, I choose to immerse myself in this crowd and engage with the real people behind the statistics. This immersion brings complexities and possibilities for changes that can improve the working conditions of digital users and even the way computer vision is designed.
My first interaction with crowdworkers occurred in 2016, in a movement that was still somewhat superficial. At that time, Gabriel Pereira, from the University of Amsterdam, and I created Recoding Art, a short film and an academic article, in which we tested how computer vision tools from companies such as Google, Facebook, and IBM behaved with images from a museum collection full of conceptual works—the Van Abbemuseum, in the Netherlands. Given that these artworks are not figurative, the relationship between what is seen and what is understood is not as straightforward as the machines might prefer. Many works, such as those by Tania Bruguera and Lucio Fontana, were not recognized by AI as art. Our research focused on analyzing these errors as valuable opportunities to gain deeper insights into the logic behind computer vision classification processes. At the end of our project, in an effort to unravel how these computer vision tools construct meanings from images, we decided to reach out to some of the crowdworkers responsible for tagging images for AI. We concluded our short film and article by asking them to describe the images from the museum collection and share whether they considered them to be art or not.
Listening to the workers goes beyond simply understanding their work realities. Often overlooked in the field of machine learning, the workers have accumulated enough experience to propose meaningful changes in the way we train machines with images. Their expertise is analogous to a scenario where a machine in a company is fully understood by those who use it daily.
That was just the beginning. Many other studies with these workers followed. Years later, in a much bolder and more in-depth initiative, I created the website Exch w/ Turkers, which allowed for real-time conversations with these workers through chat windows. This project emerged during the COVID-19 pandemic, making the website not only a space for dialogue but also a place for reflection and speculation about the future of work, particularly as the home office environment—once more common to these crowdworkers—had become the norm for many of us. Exch w/ Turkers culminated in a book where I compiled a selection of excerpts from the conversations that took place on the website. The book was produced nearly a year after the site launched, after the five participating crowdworkers (Julio, Sonia, Ananda, Reylin and Brianne) had reread their responses and added footnotes to the excerpts, either to expand upon or to challenge their previous answers. It was during this project that I met Julio Kramer, a Brazilian who has been tagging images on AMT for ten years. Julio became a key collaborator in my ongoing research, engaging in discussions and speculations about how the training of computer vision models could be improved.

The website Exch w/ Turkers, where MTurkers could talk with the audience and with themselves
This intense and long-term exchange through Exch W/ Turkers helped me realize that listening to the workers goes beyond simply understanding their work realities. Often overlooked in the field of machine learning, the workers have accumulated enough experience to propose meaningful changes in the way we train machines with images. Their expertise is analogous to a scenario where a machine in a company is fully understood by those who use it daily. When technicians decide to improve the machine’s performance, even altering its structural components, they also seek input from those who work with it regularly.
This approach led to the creation of my feature film Acapulco. In this experimental documentary, AI experts and crowdworkers were given postcards printed with images used to train computer vision systems. After weeks of engaging with these images, they provided feedback on what they observed and how the images could be used to improve the training of a computer to “see.” Much of the feedback from the crowdworkers included bold and creative ideas, demonstrating that alternative methods for training computer vision are indeed possible.
Through years of working closely with crowdworkers who train computer vision, we’ve produced films, academic articles, and other formal research materials and have also gained insights, speculations, and less formalized ideas that have the potential to transform fundamental practices and concepts within computer vision. While these proposals may seem abstract or conceptual for a pragmatic programmer, they highlight an important truth: computing is the construction of reality through a specific language—programming. And every language originates from speculative ideas.
In the last two years, first as a researcher at the Collegium Helveticum in Zurich and then at the Leuphana Institute for Advanced Studies in Lüneburg, I developed new machine training methodologies via images with the crowdworkers. In this paper, I present some of these proposals, which I call “retraining,” perhaps to emphasize that the current training paradigms in computer vision are not immutable.
RETRAINING 1: What If…?
If you ask a programmer why tagging an image is important for computer vision, you will likely get a response like this: Tagging is fundamental for training computer vision algorithms to interpret images or generate similar ones. Tagging an image involves assigning descriptive keywords or labels to it. These tags categorize the image, making it easier to search for and identify based on its content. Tags can include objects, people, locations, or any other elements present in the image.
However, if you ask a historian what it means historically to systematize material reality through specific elements of images, they will likely talk about colonization. Images such as maps, illustrations, and later, photographs have been essential tools in the projects of invasion and exploration of communities and territories. I come from a country that was divided by a map even before it was invaded by the Portuguese. Through the system of hereditary captaincies, Brazil was divided into 15 horizontal bands, each granted to members of the nobility or Portuguese merchants. This division, made without ever setting foot on the land, separated Indigenous communities, illustrating how systematization often imposes another reality—the reality of those who observe from a distance. Brazil is not an exception in this practice of dividing territories from afar through images. The African continent, too, was divided in 1878 by European powers and the United States in a room in Berlin with the help of maps.
This colonial digression aims to highlight that the practice of isolating and identifying elements from a distance via images is part of a larger ideology that is inherently violent. Tagging images is the virtual equivalent of this act. This is why the concept of “retraining” that I’ve discussed most frequently with crowdworkers revolves around the practice of tagging images. Is it possible to envision a less invasive and less decontextualized approach? One that suggests rather than defines? An approach that encompasses the most likely possibilities but also considers those that are less probable yet still possible?
It is possible, but the process also requires a readjustment of the images that will receive this tagging. To underscore the extractivist logic inherent in the image tagging process, I collaborated with programmer Bernardo Fontes to create a piece of programming code during my time as a researcher in the Histories of AI: A Genealogy of Power group at the University of Cambridge between 2021 and 2022. The Python code we developed was designed to read the data from tagged areas in nature images within Google’s Open Image dataset, widely used to train computer vision systems.
The code identifies and discards these selected/tagged areas, leaving behind images composed only of the unselected regions—areas no longer considered important for computer vision. These informational gaps highlight the extractivist nature of the tagging process while also provoking thoughts on the systemic destructuring that computer vision imposes on territories, animals, plants, and more. We named this reverse-engineering experiment Decanonization, drawing from some technical papers on computer vision that use the term “canonization” to describe the process of tagging elements to be highlighted within bounding boxes.
The incomplete images became the foundation for creating an exercise that subverts the traditional tagging process—What If…? Instead of using tagging to complete images, What If…? employs decanonized images as a way to expand the assertive logic of traditional tagging. With images now containing empty areas, crowdworkers are no longer tasked with defining what they see, but rather with imagining what could potentially exist in those spaces.
What If…? generates a set of images with metadata that is no longer static, offering not just a single “right” answer but a “range of right” answers with varying degrees of probability. Below is the exercise carried out in the initial test of What If…?

What might exist in the blank area?
Add another option to the list below.
Your choice should be reasonably probable, unlike an unlikely option such as an (elephant).
Make sure your choice aligns with the overall probability of the existing options, except for the (elephant).
bird
aeroplane
balloon
parachutist
kite
drone
fireworks
day moon
more cloud
(an elephant)
Note to the reader: The inclusion of the “elephant” option is not simply a way to partially limit the imagination of crowdworkers. It’s intended to create training instructions that are engaging and not boring or authoritarian. To date, no crowdworker in closed sessions to teste this exercise I have worked with has ever encountered a flying elephant—but that could always change.
RETRAINING 2: Polyphony
Amazon Mechanical Turk (AMT) is the most paradigmatic platform for understanding the reality of the working conditions of crowdworkers involved in training computer vision models. AMT was created by Amazon, a major US tech company, positioning the platform squarely within the neoliberal logic of big tech. But AMT is also paradigmatic because it represents a work model where individuals perform common tasks while being completely separated from one another. This worker isolation is a defining feature of the gig economy.
Beyond the urgent need for improving working conditions, worker isolation has significant consequences for machine learning. One of the most complex losses is in the understanding of images. Isolation prevents crowdworkers from engaging in practices essential to constructing complex meanings: dialogue, dissent, and, most importantly, the creation of shared understanding.
On AMT, the MTurkers are responsible for completing microtasks that computers cannot efficiently handle, known as Human Intelligence Tasks (HITs). These tasks are varied and range from transcribing text and web research to completing surveys and describing images for computer vision. However, these HITs are isolated actions. While the workforce is global, the crowdworkers are scattered, with no formal means of communicating or organizing through the platform. They do not need to interact or collaborate to complete tasks, making it difficult for them to build social support or mobilize. Nonetheless, MTurkers, activists, and academics have formed independent organizations and initiatives like Turkopticon and TurkerNation to address isolation and lack of social support, restricted agency, absence of transparency and accountability, along with other ethical concerns.
Beyond the urgent need for improving working conditions, worker isolation has significant consequences for machine learning. One of the most complex losses is in the understanding of images. Isolation prevents crowdworkers from engaging in practices essential to constructing complex meanings: dialogue, dissent, and, most importantly, the creation of shared understanding. In one example from the Acapulco film project, I sent crowdworkers a postcard featuring an intriguing image from a computer vision training dataset. The image showed a flat surface covered in what appeared to be the remains of something red, with a knife lying nearby. The workers offered conflicting interpretations. Some suggested it was something mundane, like a red fruit cake messily cut on a table, while others thought it could depict something more serious—a crime scene, with the red being human or animal viscera cut by the knife. Despite their starkly different interpretations, a crowdworker from the Philippines, who preferred to remain anonymous, summed up the situation: “In any case, it looks like the knife is involved in whatever this mess is.” This simple observation—drawn from their collective input—led to a crucial realization: the knife was a key element of the image, regardless of the broader scene’s interpretation.
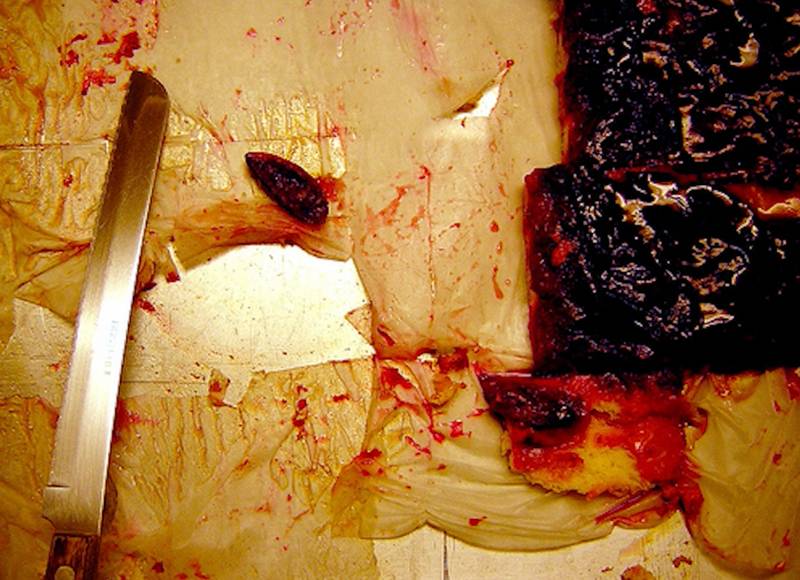
An ambiguous image in one of the computer vision training datasets. A crime scene? Or a red fruit cake?
This led me to reflect on the process of retraining. The project envisioned the description of images for computer vision as a large, polyphonic circuit of crowdworkers. While this circuit is chaotic, and much of it may seem uncomputable, points of agreement—like the significance of the knife—emerge from the polyphony. This retraining does more than identify key elements; it adds complexity to images by drawing on the richness that collective interpretation brings. In essence, everything exists in the “between”—between people, between images, and between multiple meanings. The resulting consensuses become training data derived not just from the isolated work of individuals but from their interaction with each other and the images. This process illustrates how polyphonic collaboration can enhance the complexity and richness of training data, making it more reflective of the multiple layers of interpretation that images can hold.


Moment A
Write a short sentence that establishes a relationship between the two images above.
Your short sentence: (fill in here)
The other person’s sentence: (here)
Improve the short sentence written by someone else for the same two images: (fill in here)
Moment B
Read someone else’s modified version of the short sentence you wrote earlier.
Your modified sentence: (here)
Improve the sentence you wrote previously about the relationship between the two images.
Your new short sentence: (fill in here)
Note for the reader: While it is true that in this proposed retraining, crowdworkers remain isolated in their individual contexts, the ability to read, evaluate, and improve upon others’ responses helps to create a prototype of a discussion arena. Though this arena is far from ideal, it expands on what was once entirely isolated and individual. Moreover, it continues to generate valuable machine training data, satisfying even the most skeptical programmers.
RETRAINING 3: Informational surfaces

A frame from the film Acapulco
The image above is a frame from the film Acapulco. At first glance, it may not seem so, but the frame represents a trivial image from one of the datasets used to train computer vision systems. However, instead of displaying the scene itself, we show only the tracking of the crowdworker’s mouse movement as they tagged and described it. This valuable approach reveals a crucial, often invisible layer of these training images. Beyond everyday scenes, these images serve as informational spaces where humans perform real manipulations. It is these manipulations that ultimately train the machines, as computers do not “see” images but interpret binary sequences of information. This retraining highlights regions of an image most important to the human worker, as they are likely the areas the mouse traverses most frequently. Yet, more than retraining, this practice acts as an invitation to “detraining.” If we seek to understand the images that train computer vision more deeply, sometimes we must refuse to look at them in the usual way.
When we recognize that computer vision is the result of real human labor, these and other retraining efforts can expand in scale. The focus of the question will shift. Instead of asking, What does computer vision see? we will move toward asking, How do we want computer vision to see?
This refusal is more plausible than it seems. The most widely used computer vision datasets are often composed of highly biased images. At first glance, they seem ordinary: scenes from daily life, natural landscapes, or cute animals. A closer look reveals that these images represent a specific way of cataloging the world. For example, the ImageNet training dataset consists of 14 million images manually tagged by crowdworkers. Many of these images come from Flickr, a platform popular in the US but less so in other parts of the world. As a result, the images disproportionately reflect Western cultural norms: Halloween and Independence Day celebrations, few Indigenous people, and an overwhelming number of pizzas and hamburgers.
Rejecting these hegemonic datasets should be a proactive act. If we stop relying on them, what should we focus on instead? This retraining suggests that, beyond the images themselves, we must also see the human manipulations that define them—such as how a simple jack-o’-lantern becomes the epitome of a “festivity.” Auditing widely used datasets like ImageNet is essential. But equally important is examining the human practices of organizing, labeling, and validating these images, as these actions are fundamental yet often overlooked. These images are not just training data—they are arenas of human labor. This final retraining proposal does not directly train computers; instead, it trains our perspective on the field of computer vision and encourages us to materialize its practices. By refusing to see the training images in the traditional way, we open our eyes to hidden processes essential for demystifying the seemingly automated nature of computer vision.
In one of many conversations with crowdworker Anand from New Delhi, we discussed how to see behind the scenes of computer vision training. Could any image from these datasets encapsulate the training process? Anand thought not. Instead, he sent me an image of his bedroom—his workspace. This is the true “synthesis image” of computer vision for both Anand and me. By looking at the movement of workers’ mouses and, more importantly, understanding their realities, we can radically retrain how computers “see” the world.

Anand’s bedroom and workspace in New Delhi, India. Credits: Exch w/ Turkers
Note for the reader: When we recognize that computer vision is the result of real human labor, these and other retraining efforts can expand in scale. The focus of the question will shift. Instead of asking, What does computer vision see? we will move toward asking, How do we want computer vision to see? Such a shift will also become a process of self-reflection—an invitation to see ourselves in the manipulation, creation, and systematization of knowledge.
CONCLUSION: Shaping
These eight years of working with MTurkers have taught me that technological systems are never purely automatic or devoid of humanity. Computer vision, like all types of AI, is a combination of human and machine agency that results in tools and worldviews that do not simply appear as if by magic. Despite efforts by big tech companies, including Amazon, the creator of AMT, to promote the false notion that AI is fully autonomous, these and many other crowdworkers demonstrate that the reality is far more complex. AI is shaped by human workers, and their contributions must be better understood and made visible if we are to create a more equitable and transparent technological landscape.
In one of many collective conversations with these crowdworkers, Sonia, a worker from Brazil, shared something that resonated deeply with me: “Working as an MTurker helps me feel useful too, because I’m shaping the future.” Her words reveal that, even in the context of a platform that isolates workers and renders them as invisible as possible, the sense of belonging through work persists. “Shaping the future” is not just a poetic phrase from Sonia. When MTurkers like her tag or describe images, they are actively participating in the construction of how the future will be interpreted and classified by machines—and, by extension, by humans who rely on these systems. I particularly appreciate the phrase “shaping the future” because it connects to the notion of practice—a daily act of creation through the small, often poorly paid tasks performed by these workers. “Shaping” implies something dynamic, prompting us to consider: How is this work shaping things? And, further: How might it be different?
Shaping new machine training methodologies with crowdworkers goes beyond simply improving machine performance. It involves placing humans at the center of this process, where they rightfully belong—as protagonists. After Sonia shared her poignant thought, she added a phrase that redefines how we should view computer vision and AI as a whole, summarizing the essence of these new training methodologies tha for eyer I am creating with them: “There are no intelligent machines, only machines with intelligent humans.”
-
 READ
READPrejudiced, racist attitudes are, of course, still a part of this problem, but crucially, they are just one part. Global white supremacy is a far bigger structure – a political and economic system that transcends national borders and shapes most of the world. Problematising it this way implies a need for much bigger solutions than simply educating people out of their prejudiced attitudes. It means completely restructuring – or indeed dismantling – those economic and political systems that maintain the supremacy of whites over non-whites.
Problematising ‘Right-wing Extremism’: Analysing White Supremacy and Government Responses to Racist Violence
-
 READ
READThrough artistic research, Seascape of Imagination is an attempt to unravel the intricate ties between South Asian transnational craftmanship practice and the nuanced processes of decoration and labour, emphasising the boat engineering craftsmanship that survived colonial and nationalist modernity. A significant aspect of this project is challenging the prevailing modern distinctions between art and craft, especially when contextualising the act of painting as a decorative aspect of the shipbuilding done by members of the fishing community.
Seascape of Imagination
-
 READ
READThe story of the Democratic Republic of Congo isn’t just about coups or Cold War power plays – it’s also a story told through rhythm, resistance, and reinvention. Soundtrack to a Coup d’État invites us to see music not as something that plays in the background of history, but as a key player in it – used by empires, reclaimed by artists, and still resonating in the voices of those who won’t be silenced.
Frontlines of Power: Sonic Politics in the Democratic Republic of Congo
-
 READ
READSystems and structures that prescribe most societal functions today, including the production and presentation of art, have little consideration for bodies performing these functions. Let us acknowledge these disparities and allow them to guide our ways of being and acting ethically.
Embodied Curating: Attuning the Body From Artistic to Political